The field of people analytics is wrestling with whether there’s any work left to do in a post-AI world. So have I.
Many products. One argument.
People analytics doesn’t just survive AI — it makes AI better. I built everything below to prove it.
Apps — the products · Stacks — the tech underneath · Parts — recurring patterns · Stats — the numbers. /portfolio for the full writeups.
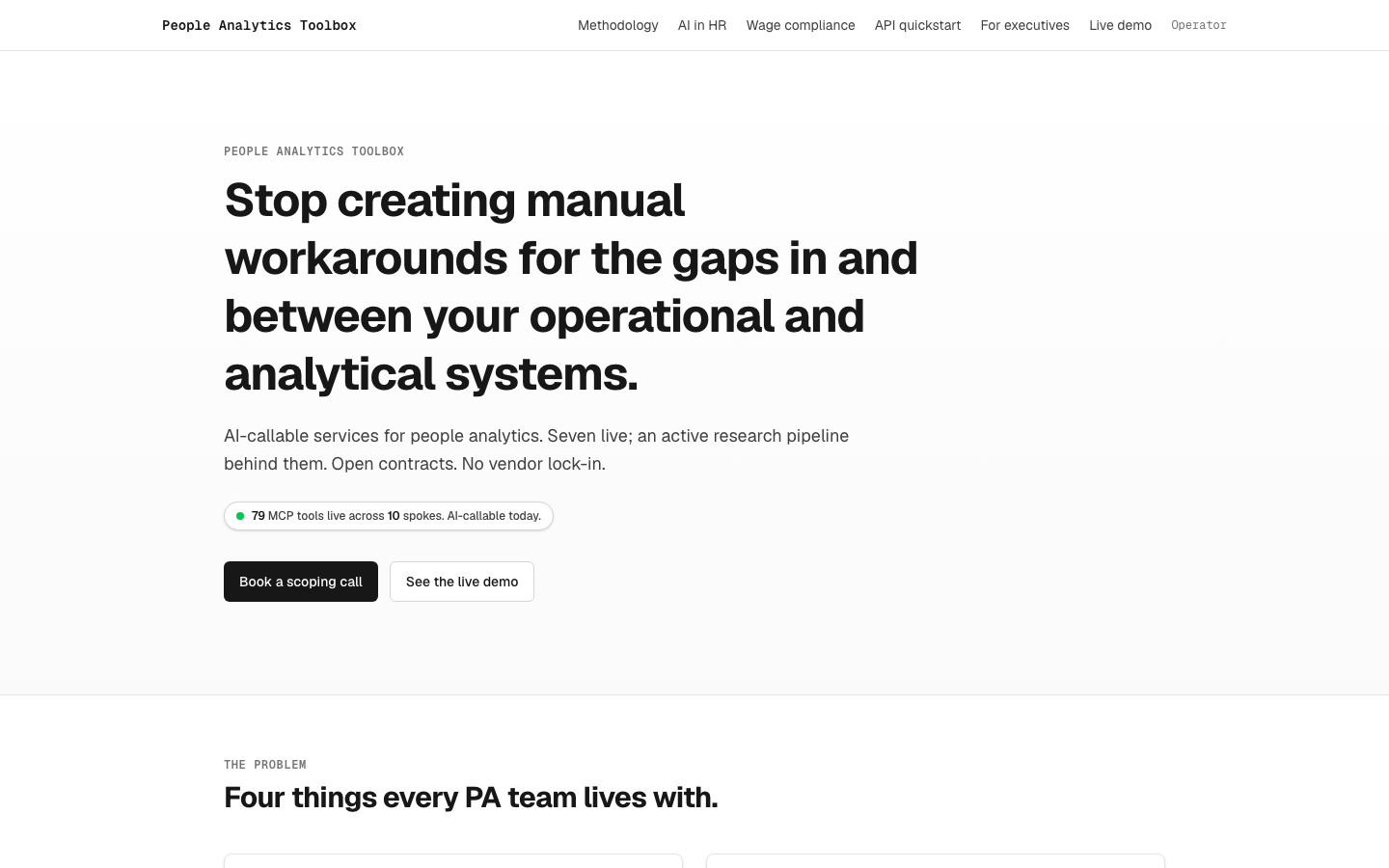
People Analytics Toolbox
LiveIndependently-versioned analytical microservices for people analytics — psychometric diagnostics, preference modeling, privacy primitives, segmentation, statistical enrichment, compensation logic, decision forecasting, metadata-grounded codegen — deployed as a single Next.js application and exposed over two transports: HTTP for engineers, MCP for AI agents. One Vercel project, one Supabase project. The behavioral and statistical foundation consumer apps compose against.
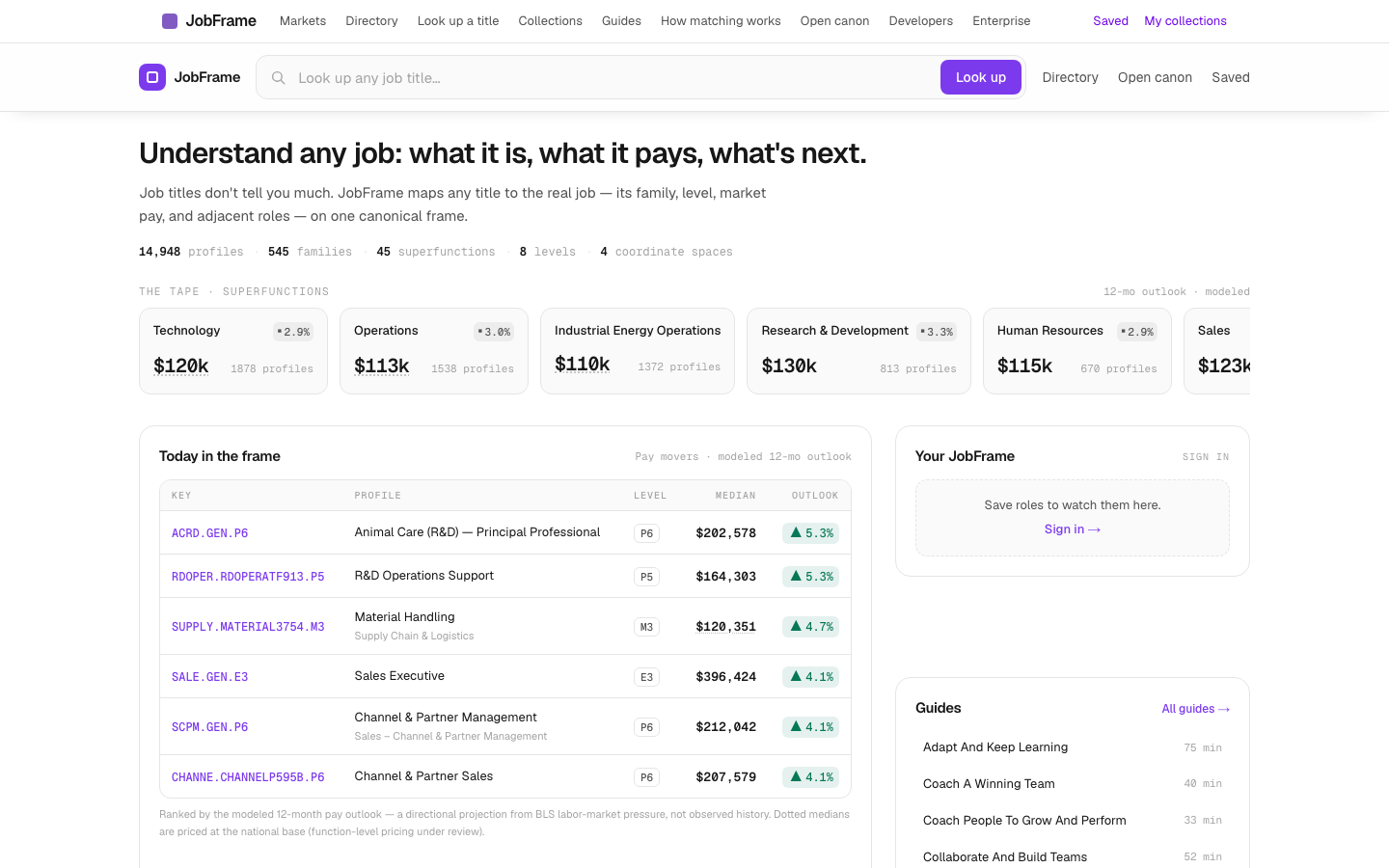
JobFrame
LiveA canonical frame for jobs — the taxonomy, the coordinates, and the pay model underneath, published as a public reference. Pantone for jobs: every role addressable, comparable, and priced.
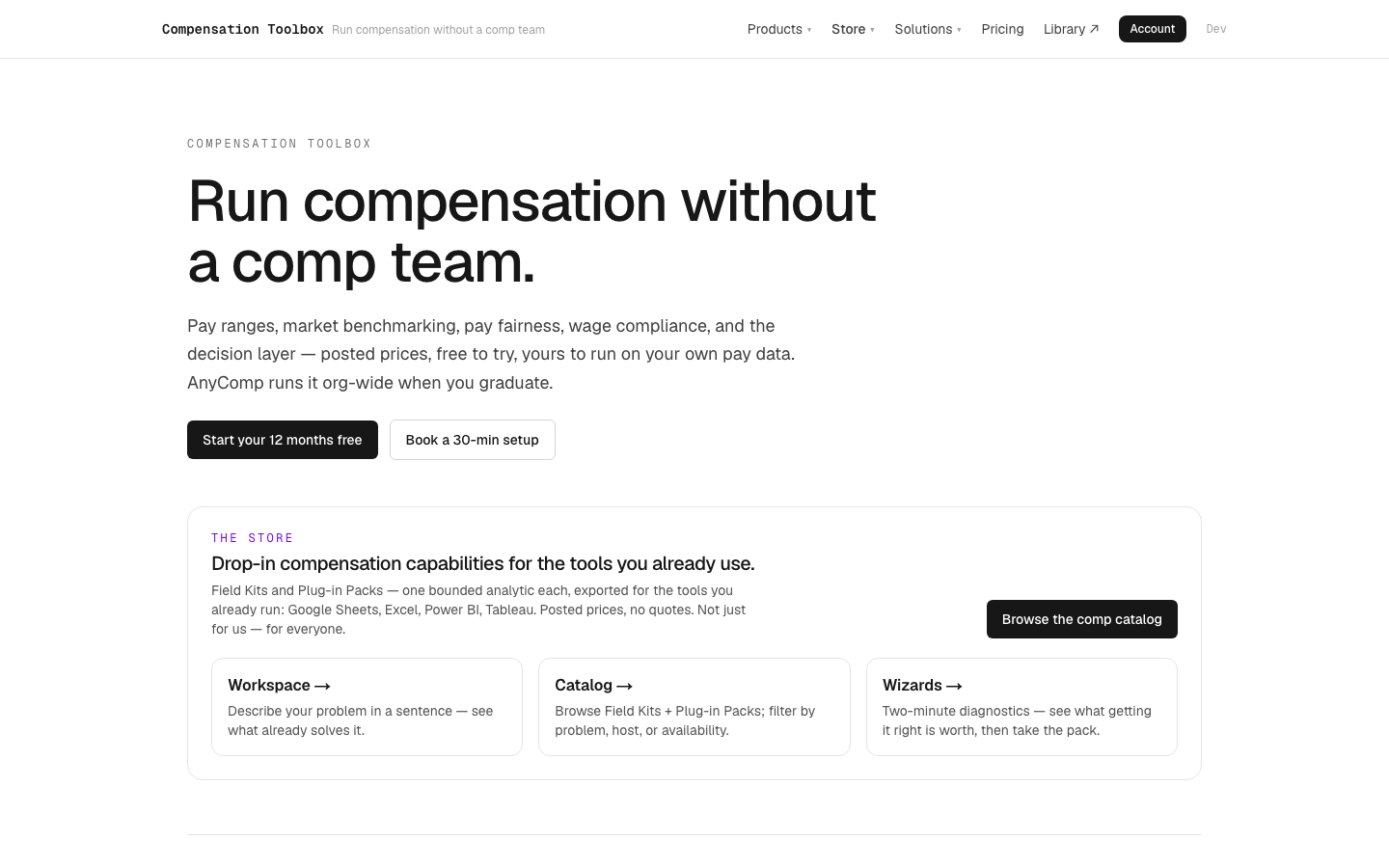
Compensation Toolbox
LiveRun compensation without a comp team. The comp-vertical sister to the People Analytics Toolbox — a self-serve store of drop-in compensation capabilities (pay ranges, market benchmarking, pay fairness, wage compliance), exported for the tools comp pros already run, with posted prices and a free tier. The same store shape as the PA Toolbox, every spoke pointed at pay.
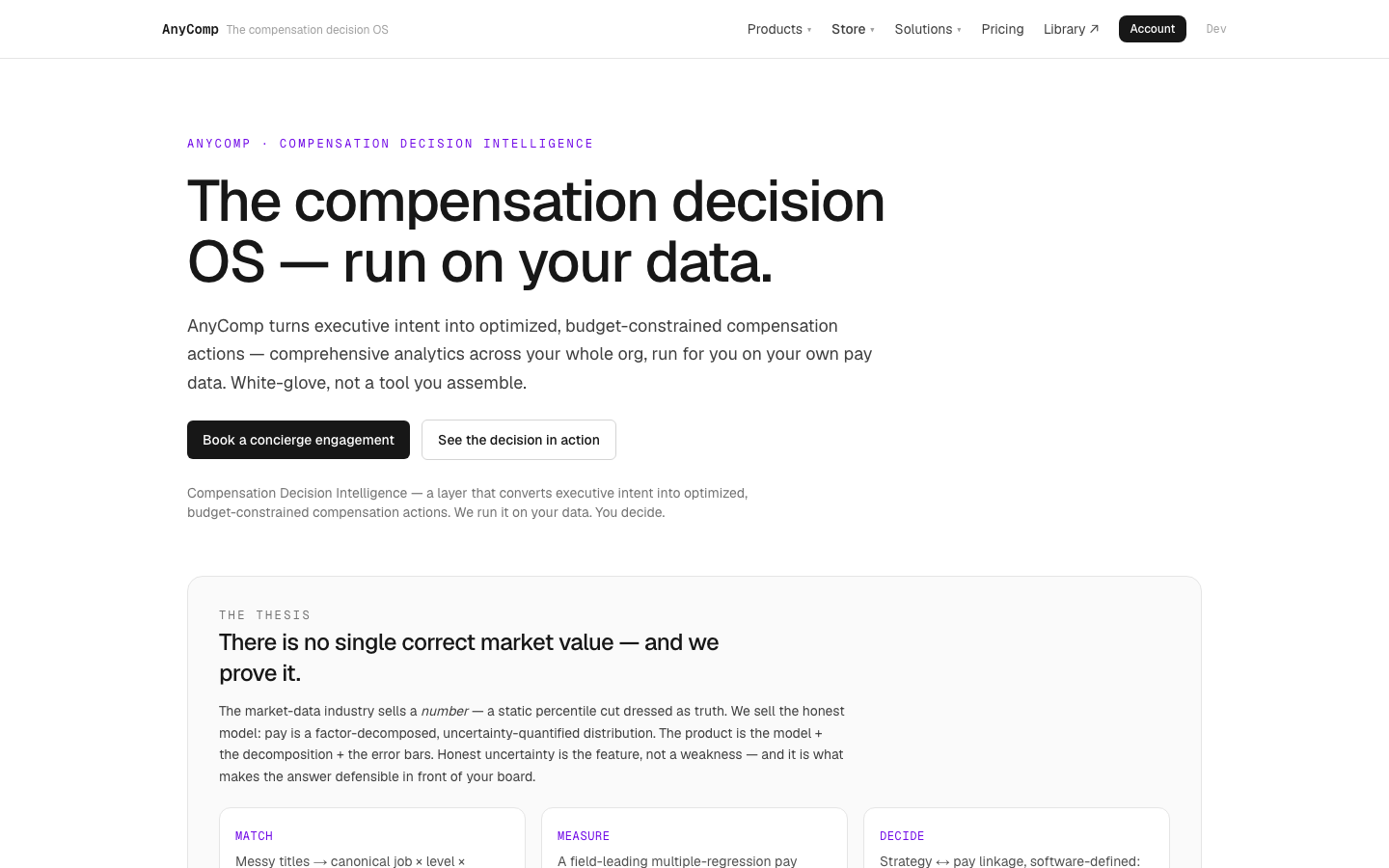
AnyComp.AI
LiveThe compensation concierge — comprehensive comp analytics plus white-glove service for executives. AnyComp.AI is the org-wide Compensation Decision OS you graduate to from the self-serve Compensation Toolbox: pay decided across all your jobs and people at once, on a replayable cycle audit. The comp parallel to Performix — a polished concierge product off the store.
Compensation Professional
LiveThe persona site for the person who owns pay without a comp function behind them — the comp analyst and the total-rewards generalist who inherited the ranges and the questions that come with them.
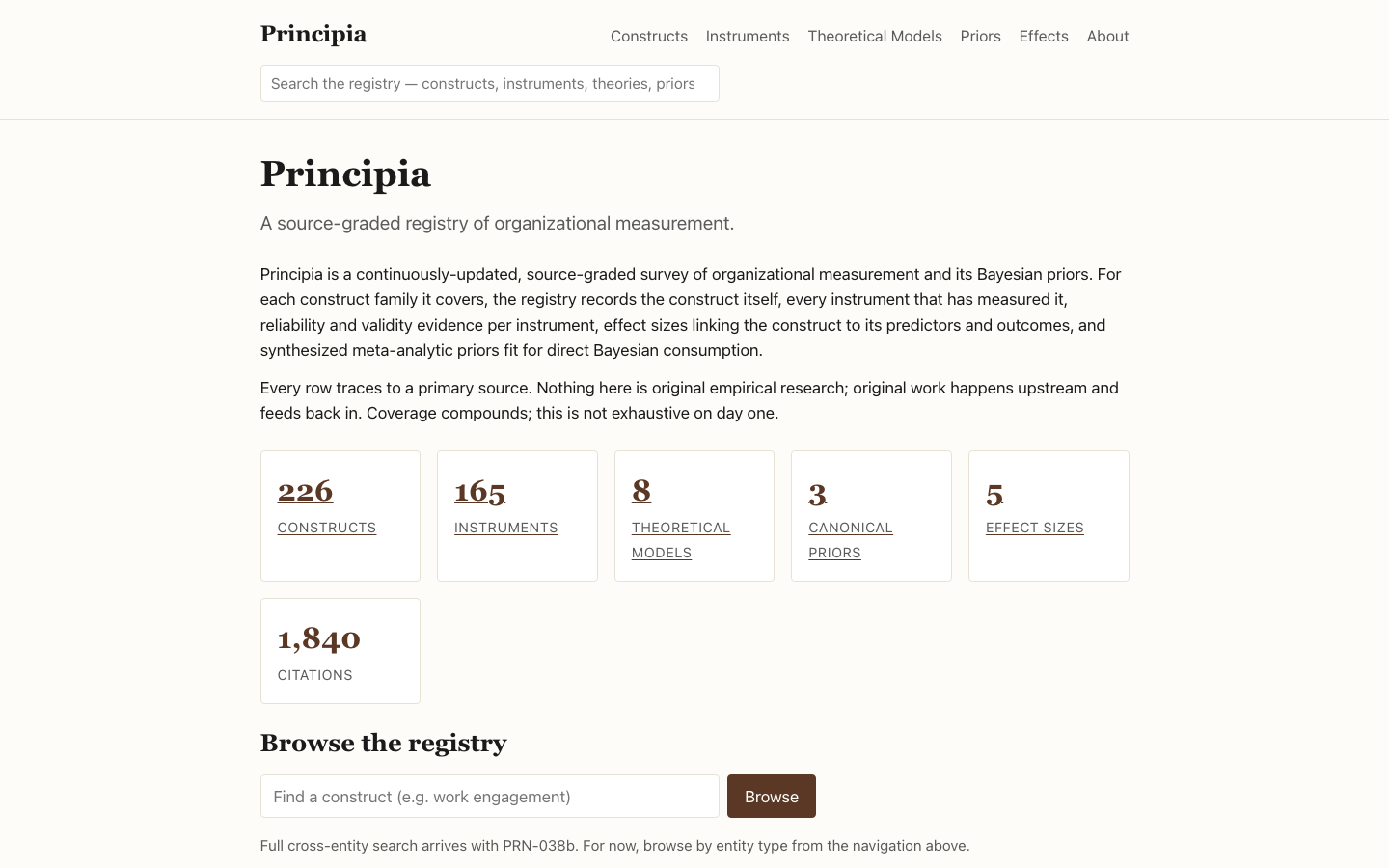
Principia
LiveThe continuously-updated, source-graded, citation-verified, Bayesian-prior-bearing registry of organizational science — a survey-not-original-research curation layer that sits on top of CanonicAI's extraction pipelines and feeds canonical priors to the rest of the portfolio over a versioned REST + MCP contract.
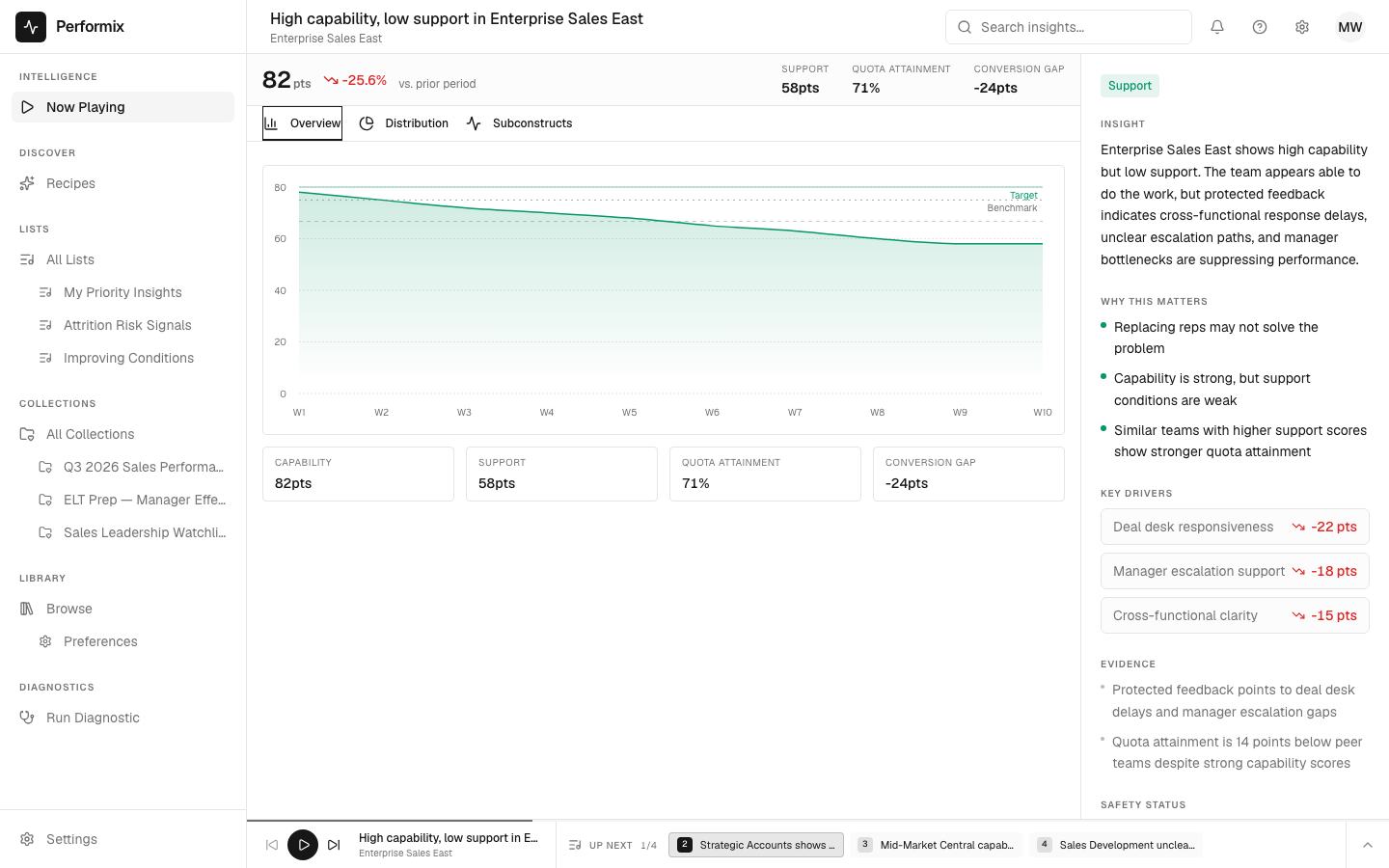
Performix
LiveThe missing layer for managing performance — Performix brings measurement science to leadership decisions, controlling the conditions that drive a team's performance, not the people (ERP runs operations, HRIS runs payroll; nothing runs performance — Performix is the system that does). The mechanism: scores teams on Capability / Alignment / Motivation / Support (CAMS), names the binding constraint, and renders one accountable action per team. Psychometric-first: the diagnostic engine is real measurement, not a language model. The foundation underneath — constructs, measures, evidence weights — is built by AI-assisted ingest of peer-reviewed I/O psychology and organizational behavior literature, which is the precondition for the product, not a gloss on top of it; AI is a consumer of that foundation, never the engine. Same instrument, three doors: sales-performance variance, AI-transformation readiness, post-acquisition integration. MVP 1 live; pre-chasm.
Bicycle Guide
LiveA bicycle for learning: the whole of a subject — the journey that would take a lifetime, in about an hour. A travel guide for a field, not a summary of it: read everything, plan the route, mark every stop worth making — honest about where the experts disagree, grounded in research, made to stick. One engine (CanonicAI's cross-book models → the Bicycle generator), many focused .guide fronts.
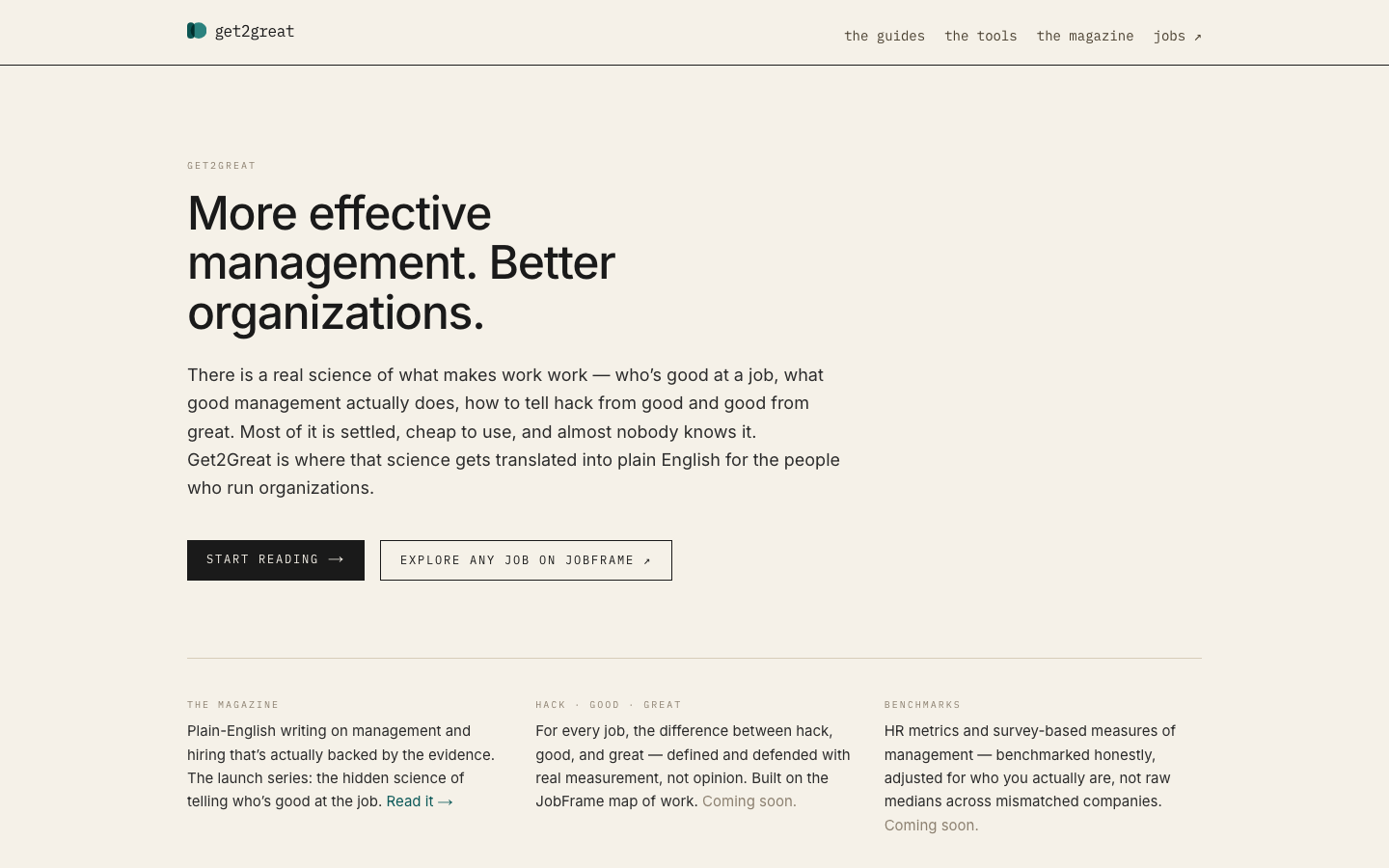
Get2Great
LiveManagement and HR for operators — the hack/good/great gradient made measurable, for the manager who has to run the team on Monday rather than study it.
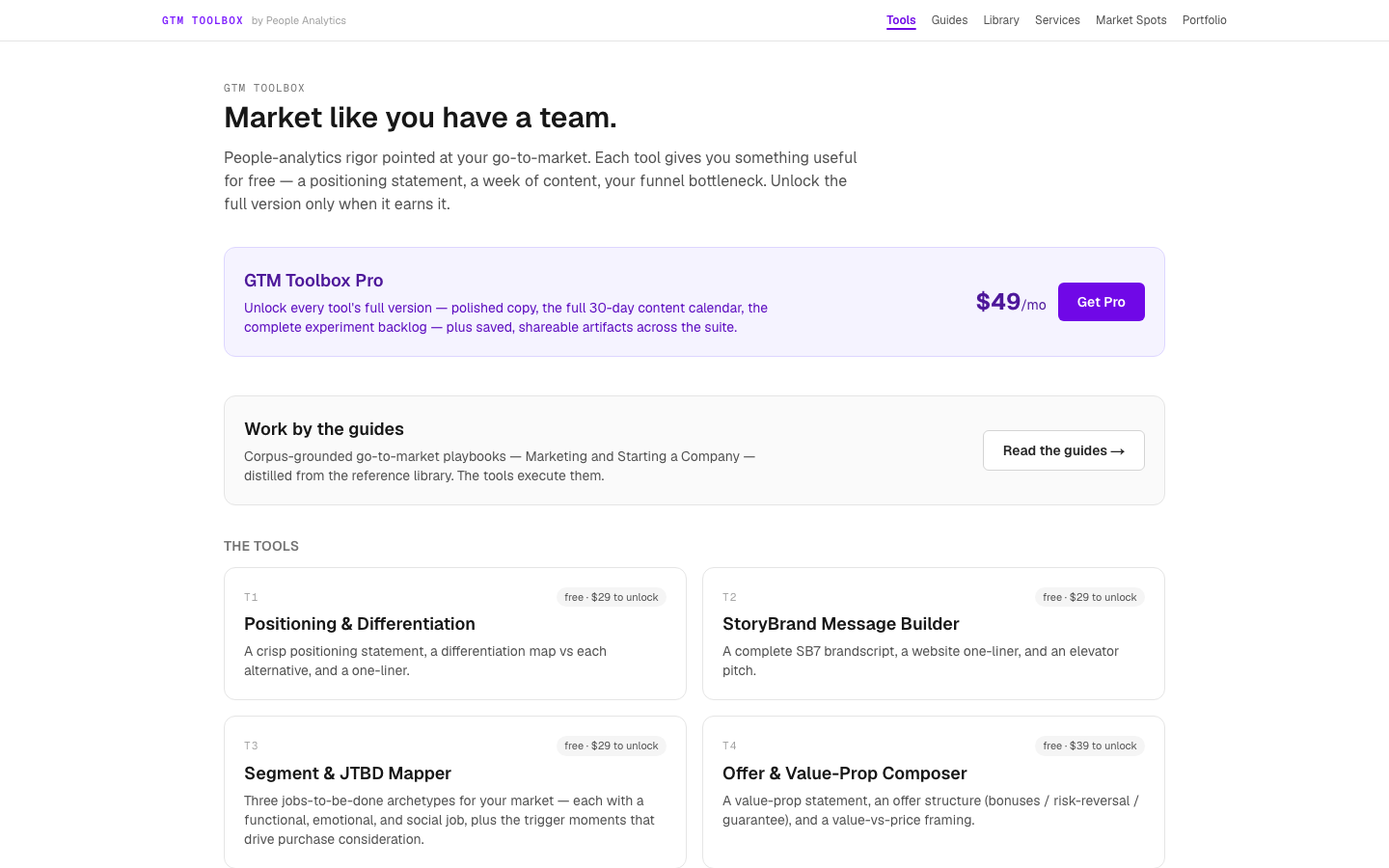
GTM Toolbox
LiveGo-to-market tooling for local businesses and small teams — the marketing and sales lane of the toolbox pattern, and the home of the persona database.
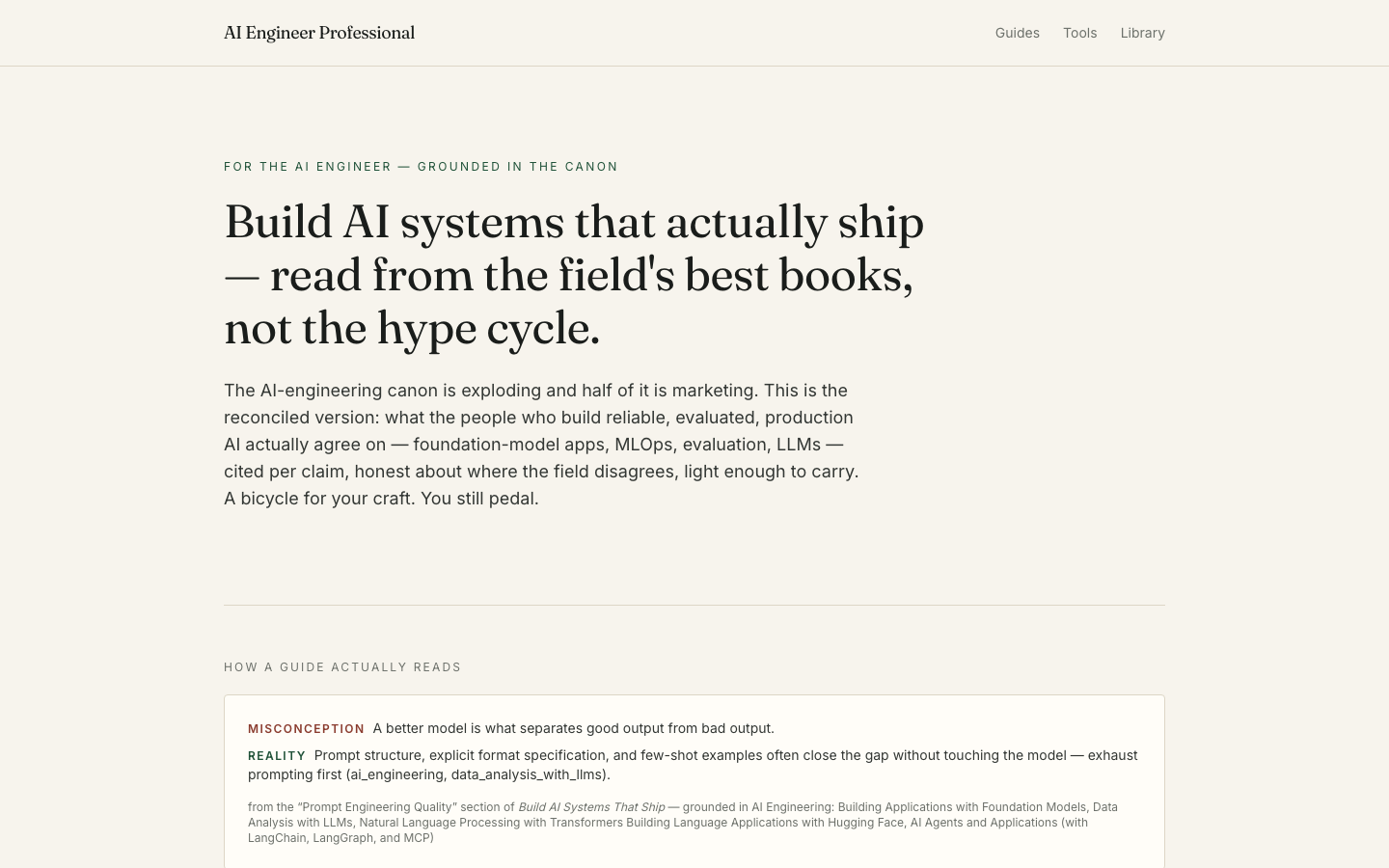
EngineerPro
LiveA persona hub for software, AI, and data engineering — three live fronts on one engine, with Journeyman, the practice tool for new engineers, folded in.
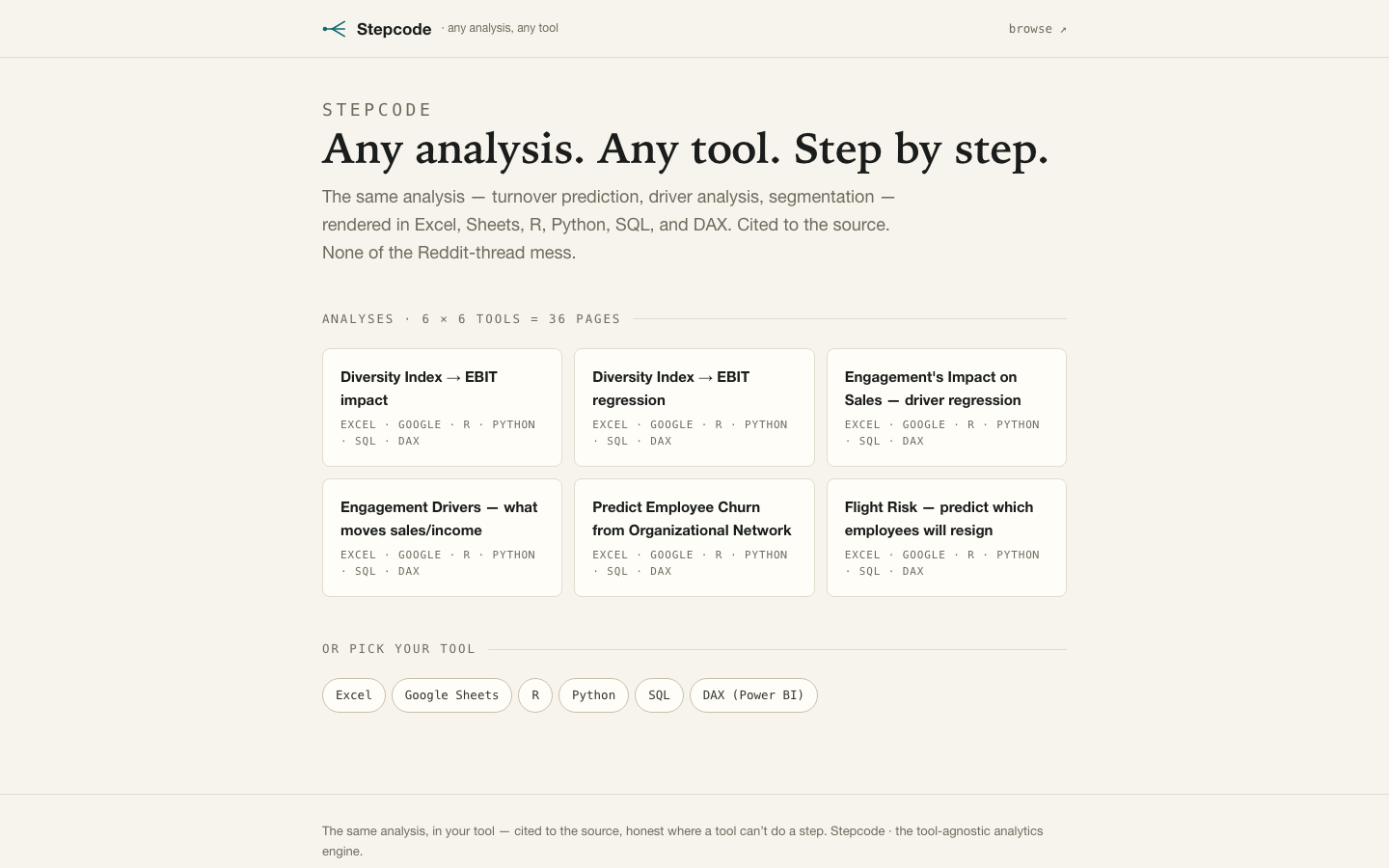
Stepcode
LiveThe same analysis, in whatever tool your organization actually runs — turnover prediction, driver regression, segmentation, rendered step by step in Excel, Sheets, R, Python, SQL and DAX, cited to the source.
DevPlane
PrivateTwo products in one project. (1) A local cockpit for multi-tool software development — assignment registry, two-phase actor handoff, coordination-event log, MCP server, CLI, Chrome extension; the operator-side measurement layer AI coding tools' agent-side metrics miss. (2) The portfolio's shared engineering brain — pattern library, architecture maps, session handoffs, cross-project assignment registry, API registry, decision log, capabilities catalog, and the capability-architecture doctrine the whole portfolio is built against.

Fourth & Two
PrivateGridiron Platform — a fantasy football platform built around four converging efforts: a GM Command Center (lineup, waivers, trades, draft, rankings), a Python analytics API (PRISM and CAMS frameworks ported to football), an Insight Card system (PRISM trend / CAMS alignment / market-signal cards composed across surfaces), and Strategy League / Football IQ (a coaching-strategy game layered on fantasy leagues with a simulation engine).
Namesake
LiveA name chosen, not stumbled upon. Every baby-naming product helps parents find names; Namesake is the only one that helps them choose one. Built on twenty years of weekly search data, a per-name composite score (SSA stats × LLM-enriched meaning × cultural-event attribution), a tournament-bracket decision UX with village voting, and a cultural-diffusion research apparatus underneath.

CanonicAI
LiveCorpus in, canonical data out. CanonicAI is the engine that turns a provided corpus — books, papers, domain documents — into canonical, queryable datasets, and owns the canonical schema + provenance the rest of the PeopleAnalyst family builds on. A production line, not a prompt.
Vela
LiveA study of being human, read through four lenses — figurative art and the museum traditions, the vocabulary of emotion, literature (including the religious and contemplative inheritance), and the behavioral science of how people form, feel, and become. A magazine — written primarily by AI from that corpus, edited by humans and shaped by reader feedback — weaves them; adaptive intelligence learns how each reader moves through the material. The figurative-art player is the room a reader can enter first — one dimension positioned in a much broader project, all of it pointed at one work: helping people replace the belief-rooted thoughts and emotional patterns that work against their lives and communities with ones that work for them.
Penwright
LiveAn AI-augmented authorship system — corpus control, packet-shaped composition, and a measurement framework that asks whether the writer is better with it, than without it, in six months.
The Family Almanac
LivePregnancy through toddlerhood, treated as a reference problem — carded here as engineering work, not as people-analytics content.
The argument
They look unrelated — enterprise people analytics, coding tools, AI-augmented authorship, fantasy football, baby naming, figurative art. Each is an instance of one wager: that the science of measuring people is the manual the AI field needs (and vice versa).
And I built all of it — every product above is software I designed and shipped. I take on a few client builds, too: web apps and early-stage analytics applications with this same perspective.